


I Pattern Architetturali del Software

Quando si inizia un nuovo progetto ci sono due tipi di sviluppatori: quelli che si lanciano subito a scrivere codice, pensando ‘intanto faccio funzionare il giro, poi lo sistemo 🤥’, e quelli che, prima di partire, spendono mesi a progettare architetture supermegacomplesse, pronte a gestire milioni di casi limite.
Secondo te dei due chi è lo Sviluppatore di Legno? 🪵
Se vuoi te lo dico io:
entrambi!
Il primo approccio soffre di una evidente carenza progettuale e di conseguenza architetturale, che porta ad un progetto monolitico composto da poche cartelle contenenti file enormi. I file hanno nomi molto significativi come main34, test87, db_non_funziona, db_ok e chi più ne ha, (peggio) ne metta.
Il secondo approccio, sulla carta più lungimirante, deriva però dal più comune vizio di superbia dei programmatori junior: voler reinventare la ruota. Progettare un’architettura da zero che sia valida e funzionale richiede un’esperienza pluriennale, la stragrande maggioranza dei progetti che nascono su architetture custom richiedono sei mesi solo per implementare una login (se va bene).
Ma cosa fa in questi casi uno Sviluppatore Vero?
Uno Sviluppatore Vero conosce i pattern architetturali. Un pattern architetturale è una struttura standard per organizzare un progetto software, definendo come i componenti (come logica, dati e interfaccia utente) interagiscono tra loro per garantire modularità, manutenibilità e scalabilità.
Uno dei problemi comuni per gli sviluppatori che entrano in corsa su un progetto è decidere dove posizionare una nuova classe. Conoscere i pattern architetturali permette tra le altre cose di rispondere in modo naturale e autonomo, senza fare figuracce con il Lead.
Vuoi sapere subito quale pattern utilizzare per il tuo prossimo progetto? Corri a scoprirlo ⬇️⬇️
Oppure non hai fretta e vuoi approfondire i pattern architetturali più comuni?
Model-View-Controller (MVC)
Partiamo dal più semplice: MVC.
MVC, che sta per Model-View-Controller, è un pattern architetturale usato nello sviluppo di software per organizzare il codice in tre componenti principali, ciascuno con responsabilità distinte:
- Model: rappresenta la logica di business e i dati. Il modello notifica la vista e il controller di eventuali cambiamenti di stato. È il cuore funzionale dell’applicazione che gestisce i dati, la logica e le regole del sistema.
- View: è responsabile della visualizzazione dei dati presenti nel modello agli utenti e dell’invio degli input dell’utente al controller. La vista è solitamente costituita da elementi dell’interfaccia utente come testo, caselle di immissione e pulsanti.
- Controller: agisce come intermediario tra Modello e Vista. Riceve input dagli utenti tramite la Vista e li elabora per aggiornare il Modello o modificare il modo in cui qualcosa viene visualizzato nella Vista.
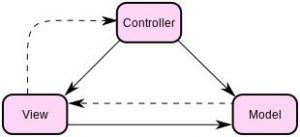
Il pattern MVC promuove l’organizzazione del codice, facilitando la gestione e la manutenzione, e supporta la separazione delle preoccupazioni, il che rende più facile modificare e testare il software in modo indipendente tra le sue componenti.
MVC è perfetto per piccoli progetti frontend o backend, personali o cooperativi, come Minimum Viable Products, Proof of Concepts o Demo. Permette di mantenere un buon compromesso tra organizzazione, semplicità e scalabilità.
Vuoi approfondire MVC? Ti consigliamo l’ottima guida di TutorialsPoint!
Model-View-Presenter (MVP)
Il pattern architetturale MVP, acronimo di Model-View-Presenter, è un modello di progettazione software utilizzato principalmente per sviluppare moduli frontend. Si tratta di una derivazione del pattern MVC e viene usato per separare la logica di presentazione dei dati dalla logica di business, facilitando così la manutenzione e il testing del codice.
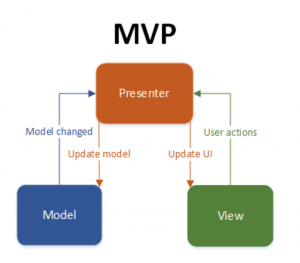
Ecco una breve descrizione dei tre componenti principali del pattern MVP:
- Model: rappresenta i dati e la logica di business dell’applicazione. Il modello notifica il presenter di eventuali cambiamenti nello stato dei dati.
- View: è responsabile della visualizzazione dei dati (l’interfaccia utente) e dell’interazione con l’utente. La view comunica con il presenter ma non contiene logica di business, limitandosi a gestire la parte grafica e gli input dell’utente.
- Presenter: funziona come intermediario tra il model e la view. Ascolta gli eventi dalla view e manipola i dati del model, poi aggiorna la view con i nuovi dati. Il presenter si occupa anche di gestire la logica di presentazione.
Il vantaggio principale di MVP rispetto a MVC è che la separazione tra la view e il model è più marcata, con il presenter che gestisce tutta l’interazione tra questi due componenti. Questo rende le applicazioni più facili da testare e manutenere.
MVP è adatto per progetti frontend di media complessità, dove la separazione tra la logica di presentazione e la logica di business diventa cruciale per mantenere un’architettura ben organizzata. Ideale per applicazioni con un’interfaccia utente più dinamica e interattiva, garantisce un buon equilibrio tra modularità, testabilità e semplicità. Si presta bene a progetti che richiedono una struttura più solida rispetto a MVC, ma senza la complessità di architetture più avanzate.
Se vuoi approfondire MVP (con esempi pratici) ti lasciamo questo ottimo articolo.
Model-View-ViewModel (MVVM)
Model-View-ViewModel (MVVM) è un pattern architetturale utilizzato principalmente nello sviluppo di applicazioni con interfacce utente complesse, specialmente per il frontend. È stato introdotto per rispondere a limitazioni di altri pattern come MVC e MVP, offrendo una separazione più chiara tra logica di business, logica di presentazione e l’interfaccia utente, migliorando la testabilità e la gestione del codice.
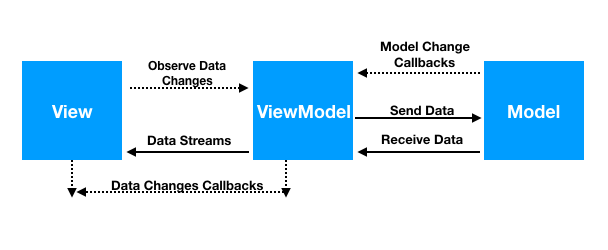
I tre componenti principali di MVVM:
- Model: rappresenta la logica di business e i dati dell’applicazione, come accade anche negli altri pattern. Si occupa della gestione delle informazioni e delle operazioni logiche, indipendentemente dalla visualizzazione.
- View: è la parte che l’utente vede e con cui interagisce. La View è composta dall’interfaccia grafica (UI), e visualizza i dati forniti dalla ViewModel. La View non contiene logica di business e la sua responsabilità principale è solo quella di presentare i dati e inviare input.
- ViewModel: è il “ponte” tra la View e il Model. Riceve gli input dalla View e li traduce in operazioni che coinvolgono il Model, aggiornando poi la View con i dati risultanti. Il ViewModel contiene la logica di presentazione, elabora i dati e li prepara per essere mostrati nella View. Non conosce direttamente la View, ma utilizza il data binding per aggiornare la UI in modo automatico quando i dati cambiano. Il data binding è una caratteristica fondamentale di MVVM e consente una sincronizzazione fluida tra View e ViewModel.
MVVM è particolarmente indicato per applicazioni frontend o mobile complesse, in cui vi è un’interazione significativa tra l’utente e l’interfaccia. È molto popolare nello sviluppo di applicazioni desktop WPF (Windows Presentation Foundation), applicazioni web React, o applicazioni mobile native Android, dove il data binding automatico migliora l’efficienza. Inoltre, è utile per progetti in cui si prevede una UI altamente dinamica con molti cambiamenti di stato e aggiornamenti frequenti.
Puoi usare questo tutorial per apprendere le basi di MVVM ed applicarle al tuo progetto!
VIPER
Il pattern architetturale VIPER è un approccio più strutturato e modulare per costruire applicazioni, specialmente utilizzato nel contesto dello sviluppo di applicazioni iOS. VIPER è un acronimo che sta per View, Interactor, Presenter, Entity e Router, e ognuno di questi componenti ha un ruolo specifico nel facilitare la separazione delle responsabilità in un’applicazione, migliorando così la testabilità e la manutenibilità del codice.
Ecco una descrizione dettagliata di ciascuno dei componenti del pattern VIPER:
- View: è responsabile di presentare i dati all’utente e catturare le interazioni utente. La view comunica con il presenter e mostra ciò che il presenter le dice di visualizzare. Non elabora dati o logica di business direttamente.
- Interactor: contiene la logica di business specifica per un particolare task o processo. L’interactor è isolato dalla UI e interagisce direttamente con le Entities per gestire i dati o le reti di operazioni. Notifica il presenter di eventuali cambiamenti nei dati.
- Presenter: agisce come il mediatore tra la View e il resto del sistema (Interactor, Router, e così via). Riceve input dalla View, li elabora tramite l’Interactor, e poi ritorna i risultati alla View. Inoltre, il presenter decide quando navigare ad altre schermate, comunicando con il Router.
- Entity: rappresenta gli oggetti di dominio o i dati di business usati dall’applicazione. Gli Entities sono utilizzati dagli Interactors e non dovrebbero essere modificati da altri componenti per mantenere la logica di business ben isolata.
- Router: gestisce la logistica della navigazione tra le schermate dell’applicazione. Il Router decide quale schermata mostrare in base all’azione dell’utente o al completamento di una certa logica di business. È spesso implementato in modo da poter facilmente cambiare il flusso dell’applicazione se necessario.
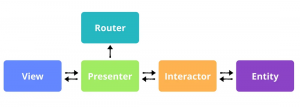
VIPER mira a risolvere i problemi di scalabilità e manutenibilità delle grandi applicazioni MVC/MVP, offrendo una chiara separazione e una più precisa definizione dei ruoli all’interno del software.
VIPER è particolarmente indicato per progetti complessi su piattaforme come iOS, dove una chiara separazione dei ruoli tra i vari componenti diventa essenziale per gestire grandi codebase. Grazie alla sua architettura modulare, VIPER offre un’elevata testabilità e facilita il mantenimento del codice a lungo termine. È perfetto per applicazioni che richiedono una gestione avanzata della logica di business e della navigazione, consentendo agli sviluppatori di mantenere il codice altamente organizzato e scalabile.
Se vuoi utilizzare VIPER per la tua applicazione ti consigliamo di leggere questo tutorial (qui il GitHub)
Domain-Driven Design (DDD)
Domain Driven Design (DDD) non è un pattern architetturale nel senso tradizionale, ma piuttosto un approccio alla progettazione software che pone al centro il dominio e la logica di business. In DDD, il software viene sviluppato seguendo strettamente le necessità e i linguaggi del dominio di business, facilitando la comunicazione tra esperti di dominio e sviluppatori. Le entità del dominio sono al centro di questo design, e intorno ad esse si costruiscono tutti gli altri aspetti dell’applicazione. DDD è particolarmente efficace in ambienti aziendali complessi dove le regole di business sono in continuo cambiamento e l’integrazione tra diverse squadre di sviluppo è cruciale.
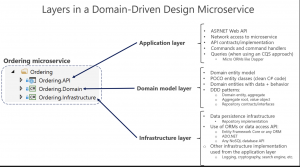
Immagine tratta da www.learn.microsoft.com
DDD non prescrive una specifica architettura software, ma offre diversi pattern che aiutano a organizzare il codice in modo che rifletta il dominio:
- Bounded Context: ambito entro cui un particolare modello di dominio è definito e applicato. Diversi Bounded Contexts possono coesistere all’interno della stessa organizzazione e interagire tra loro, ma all’interno di ciascuno, il modello e il linguaggio devono essere internamente consistenti.
- Entities: oggetti che sono definiti dalla loro identità, piuttosto che dai loro attributi.
- Value Objects: oggetti che vengono definiti dai loro attributi e non hanno un’identità.
- Aggregates: una collezione di oggetti (Entities e Value Objects) che vengono trattati come un’unità singola per le operazioni di persistenza.
- Repositories: forniscono un’interfaccia per accedere agli Aggregates, nascondendo i dettagli della persistenza.
- Domain Events: eventi che sono significativi dal punto di vista del dominio e che indicano cambiamenti di stato rilevanti.
- Services: quando una certa operazione o attività non appartiene naturalmente a nessuna Entity o Value Object, può essere definita in un Service, che può essere di dominio o applicativo.
Domain-Driven Design è ideale per progetti di grande complessità dove il dominio del business è al centro dello sviluppo. Questa metodologia favorisce una stretta collaborazione tra gli sviluppatori e gli esperti del dominio, garantendo che l’architettura dell’applicazione rispecchi accuratamente i processi e le regole del business. DDD è particolarmente efficace in contesti aziendali con requisiti intricati e in evoluzione, permettendo di mantenere un’organizzazione del codice chiara e orientata ai concetti chiave del dominio, migliorando così la manutenibilità e la flessibilità a lungo termine.
E’ impossibile imparare tutti i segreti di DDD con un semplice tutorial, tuttavia se vuoi approfondire questo vasto mondo ti consigliamo questa ottima pubblicazione.
Command Query Responsibility Segregation (CQRS)
CQRS è un pattern che separa le operazioni di lettura (query) dalle operazioni di scrittura (command) su un modello dati. Questo approccio permette una maggiore flessibilità e scalabilità delle applicazioni, specialmente in contesti con grandi volumi di dati e requisiti di performance elevati. Utilizzando CQRS, si possono ottimizzare separatamente le strategie di lettura e scrittura, sfruttando al meglio le tecnologie e le architetture disponibili, come i database NoSQL o i sistemi distribuiti.
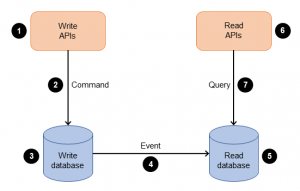
Concetti Chiave di CQRS
- Separazione delle Responsabilità: in CQRS, le funzionalità di lettura e scrittura sono implementate separatamente, permettendo di ottimizzare, scalare e gestire sicurezza, performance e complessità in maniera indipendente per ciascuna delle due operazioni.
- Modello di Scrittura (Command Model): gestisce la logica di business e la validazione, e modifica lo stato del sistema accettando comandi. È responsabile per garantire che tutte le modifiche allo stato siano consistenti e valide.
- Modello di Lettura (Query Model): fornisce una vista ottimizzata dei dati, progettata per velocizzare le operazioni di lettura. Può essere strutturata in modo molto diverso dal modello di scrittura, spesso denormalizzata per migliorare le prestazioni delle query.

CQRS è un pattern avanzato che può essere integrato in qualsiasi altra architettura, soprattutto backend come MVC o DDD, per migliorare la separazione tra operazioni di lettura e scrittura. È particolarmente utile in progetti con elevate esigenze di scalabilità o complessità dei dati, dove ottimizzare le performance e mantenere una chiara distinzione tra il flusso di dati in ingresso e in uscita è fondamentale. CQRS permette di gestire scenari complessi in modo efficiente, migliorando la manutenibilità del sistema e facilitando l’evoluzione delle funzionalità senza compromettere l’integrità del codice.
Ricordati
I pattern architetturali offrono agli sviluppatori un vocabolario comune e delle linee guida chiare per strutturare applicazioni software. Conoscere questi pattern e sapere quando applicarli permette di risolvere problemi comuni di progettazione, migliorare la comunicazione tra membri del team, e costruire sistemi robusti e mantenibili.
Ti lasciamo un breve riepilogo che ti sarà molto utile per il prossimo progetto ⬇️⬇️
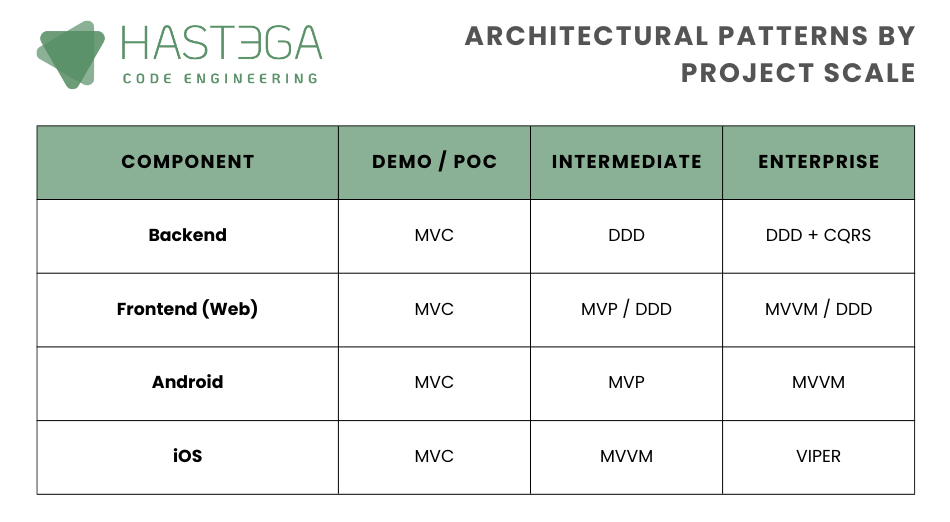

Codenauts è lo spin off di Hastega dedicato alla formazione nel mondo del software, contribuendo a plasmare i junior developer attraverso percorsi pratici e innovativi.
E’ il momento di dimostrare quanto vali.
Iscriviti al Selection Day 2024 e diventa uno dei 12 aspiranti Codenauts.
Una Coding Challenge a fianco dei professionisti Hastega: partecipa, dimostra il tuo valore e cambia il tuo futuro.


