


Ti spiego perché ‘come chiamo questa variabile’ è una domanda da Sviluppatore di Legno

Nel vasto mondo dello sviluppo software, il nome delle variabili può sembrare un dettaglio minore, quasi una semplice formalità dopo ore di logica e algoritmi complessi. Tuttavia, il modo in cui nominiamo le funzioni e le variabili può avere un impatto notevole sulla leggibilità e sulla manutenibilità del codice. In questo articolo vi spiegheremo come gli Sviluppatori Veri affrontano questa sfida!
Ricominciamo da zero: cos’è una Variabile?
Il concetto di variabile è fondamentale nel mondo della programmazione, tanto che è sicuramente una delle prime definizioni che incontriamo nel percorso di studi: “Una variabile è un contenitore di dati destinato a contenere valori, suscettibili di modifica nel corso dell’esecuzione di un programma. Una variabile è caratterizzata da un nome. Puoi scegliere quasi qualsiasi nome per la variabile, a patto di seguire alcune semplici regole formali del linguaggio di programmazione”.
Che sia la scuola elementare, superiore o un corso post diploma, un concetto su cui i docenti fanno spesso leva è la possibilità di assegnare un nome qualsiasi alle variabili. Sicuramente è un ottimo metodo per trasmettere il concetto che ciò che conta di una variabile non è il nome ma il valore che assume in un determinato istante di esecuzione. Giustissimo, peccato che abbia la spiacevole conseguenza di lasciar intendere allo studente che il nome è una semplice formalità a cui non dare nessun peso.
Il peso delle parole nel codice
Durante l’emergenza COVID-19, quando molti cittadini cercavano di accedere al portale dell’INPS per richiedere il bonus di sostegno economico, si scoprì che nel codice sorgente della piattaforma appariva una variabile chiamata “pippo”, un nome evidentemente poco professionale per un contesto di tale importanza. Probabilmente l’INPS era piena di Sviluppatori di Legno…
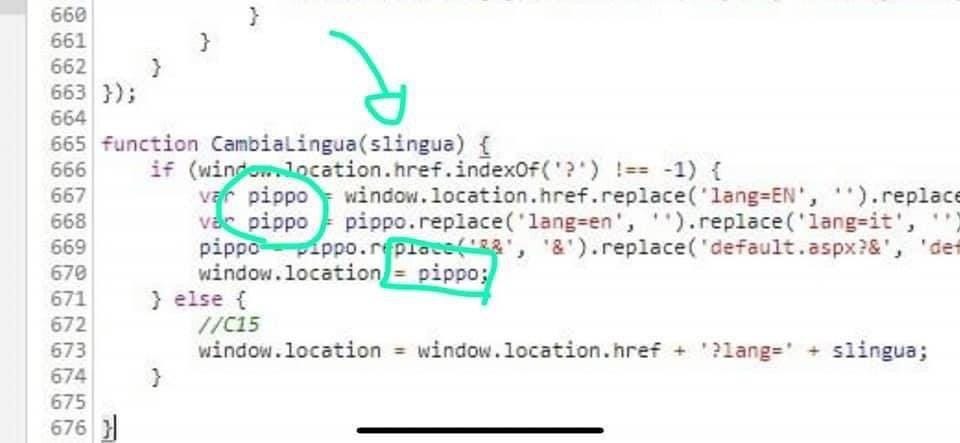
Le variabili sono i mattoni fondamentali di ogni programma. Un nome ben scelto trasmette immediatamente il suo ruolo e il suo scopo all’interno dell’applicazione. Ma, come spesso accade, i neofiti tendono a perdere tempo prezioso cercando il nome “perfetto”, riflettendo una mancanza di esperienza. Oppure non ci pensano proprio, assegnando un nome generico come “Pippo” che può suggerire una scarsa comprensione del contesto o una fretta ingiustificata, entrambi indesiderabili.
Quindi, quali sono le regole che solo i veri esperti padroneggiano?
Partendo dai fondamentali, un buon nome di variabile deve essere:
- Consistente: in linea con le convenzioni di naming, sia del linguaggio che del progetto
- Descrittivo: chiaro e specifico al contesto.
- Conciso: abbastanza breve da essere facilmente leggibile.
Le convenzioni di Naming
Le convenzioni di naming, essenziali per garantire la leggibilità e la manutenibilità del codice, variano significativamente tra i linguaggi di programmazione. Nel linguaggio Java, ad esempio, è comune utilizzare il camelCase, dove ogni nuova parola inizia con una lettera maiuscola, ad eccezione della prima (es. nomeVariabile). Questo stile è favorito per la sua chiarezza, specialmente nelle dichiarazioni di classi e metodi. In Python, invece, prevale lo snake_case, che separa le parole con un underscore (es. nome_variabile), rendendo il codice particolarmente leggibile e in linea con le PEP (Python Enhancement Proposals) standards.
Altri stili come il kebab-case (es. nome-variabile), comuni nel mondo del web development, sono spesso utilizzati in linguaggi che interagiscono con il HTML e CSS, dove gli identificatori non possono contenere spazi o caratteri speciali altrimenti. Il PascalCase, simile al CamelCase ma con la prima lettera sempre maiuscola, è spesso adottato in C# per nomi di classi e interfacce, riflettendo le convenzioni di .NET Framework. Queste convenzioni non solo aiutano a mantenere il codice organizzato ma facilitano anche il lavoro di squadra, assicurando che tutti i membri possano leggere e comprendere rapidamente il codice altrui.
Puoi evitare di commentare il codice con le Variabili Descrittive
La scelta dei nomi delle variabili dovrebbe essere sempre intenzionale e mirata a riflettere il loro scopo specifico all’interno del codice. Questo non solo migliora la leggibilità del codice, ma aiuta anche altri sviluppatori a comprendere rapidamente la funzionalità senza dover decifrare ogni operazione. Un nome di variabile efficace dovrebbe fungere da mini-documentazione, chiarificando il ruolo della variabile nel contesto del flusso logico.

Per illustrare questo concetto, consideriamo il seguente metodo Java utilizzato in un contesto backend per aggiornare un record utente:
public User update(String userUuid, User user) throws UserNotFoundException {
User userToUpdate = userQueriesRepository.findOne(userUuid);
if (user.getFirstName() != null) {
userToUpdate.setFirstName(user.getFirstName());
}
if (user.getLastName() != null) {
userToUpdate.setLastName(user.getLastName());
}
if (user.getEmail() != null) {
userToUpdate.setEmail(user.getEmail());
}
return userCommandsRepository.update(userToUpdate);
}
In questo snippet, la variabile userUuid rappresenta l’identificativo unico dell’utente, essenziale per localizzare l’utente specifico nel database. La variabilità nel nome, “UUID”, indica chiaramente che si tratta di un identificatore univoco, conforme alle convenzioni di naming per chiarire il suo contenuto.
La variabile user rappresenta l’oggetto contenente i dati dell’utente da aggiornare. È una rappresentazione generica di un utente all’interno del sistema, il che la rende immediatamente comprensibile a chi legge il codice.
userToUpdate è una variabile particolarmente ben nominata: indica un oggetto User che sta per essere aggiornato con nuove informazioni. Questo nome aiuta a distinguere tra l’oggetto user ricevuto come parametro, che potrebbe contenere solo alcuni campi aggiornati, e l’oggetto userToUpdate che è stato recuperato dal database e che verrà modificato e poi salvato.
Ogni chiamata di metodo, come setFirstName, setLastName, e setEmail, aggiunge al contesto fornendo una chiara descrizione di quale aspetto dell’oggetto userToUpdate viene modificato, seguendo una nomenclatura che spiega inequivocabilmente l’azione eseguita.
Ogni nome utilizzato in questo metodo serve quindi per un duplice scopo: descrivere il contenuto delle variabili e indicare il loro ruolo nel flusso di aggiornamento dell’utente, facilitando così la comprensione e la manutenzione del codice.
… ma non esagerare!
Ricorda che la concisione dei nomi delle variabili è fondamentale per mantenere il codice pulito e accessibile. Trovare il miglior compromesso tra descrittività e brevità richiede un equilibrio delicato: un nome deve essere abbastanza lungo da essere informativo ma sufficientemente breve per non appesantire il codice. La chiave sta nell’eliminare parole superflue mantenendo quelle essenziali che trasmettono il significato più efficacemente.
Ad esempio, consideriamo una variabile chiamata dataOfTheUserRegistration. Mentre il nome è estremamente descrittivo, è anche prolisso e potrebbe essere semplificato senza perdere il suo significato essenziale. Un’alternativa più concisa potrebbe essere userRegDate. Questo nome conserva l’informazione cruciale—che si tratta della data di registrazione dell’utente—ma in modo molto più snello.
Un altro esempio può essere trovato in una variabile originariamente chiamata outputValueOfTheCalculation. Questo può essere ridotto a calcResult o semplicemente result, a seconda del contesto. Qui, “outputValueOfThe” è ridondante, dato che “result” implica già che si tratta del valore di uscita di un calcolo.
Questo compromesso tra descrittività e brevità è cruciale per scrivere codice che sia non solo funzionale ma anche elegante. I nomi delle variabili dovrebbero funzionare come guide chiare ma discrete nel codice, supportando la leggibilità senza interrompere il flusso logico o visivo del programma. Adottando questo approccio, gli sviluppatori possono migliorare significativamente la manutenibilità e la comprensione del loro codice, beneficiando l’intero ciclo di vita dello sviluppo software.

Codenauts è lo spin off di Hastega dedicato alla formazione nel mondo del software, contribuendo a plasmare i junior developer attraverso percorsi pratici e innovativi.
E’ il momento di dimostrare quanto vali.
Iscriviti al Selection Day 2024 e diventa uno dei 12 aspiranti Codenauts.
Una Coding Challenge a fianco dei professionisti Hastega: partecipa, dimostra il tuo valore e cambia il tuo futuro.


